
LLM推理过程
大约 3 分钟
最近真是高产,其实这些东西也断断续续的学了很久了
直到最近一周,才有一种连点成线的感觉
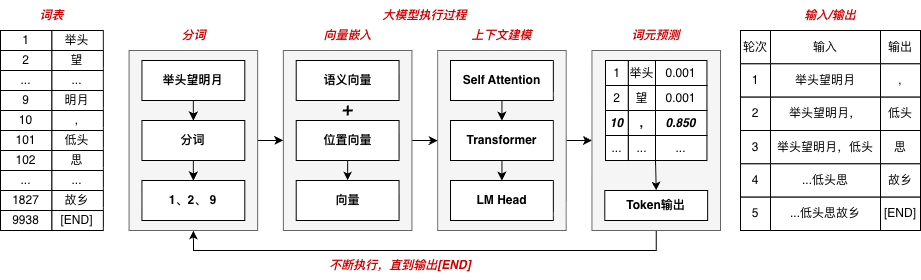
先看上面古诗接龙的例子,LLM其实就是一轮一轮的猜下一个词
Tokenize: 把文本切分为token序列
经过这一步之后,文本将被拆分为token序列,用于后续的向量查找
文本在预处理阶段,经过tokenize(分词)和embedding(嵌入),转为机器可以理解、计算的向量:
- 加载
tokenizer,也就是一个几乎覆盖所有字词的静态词表,格式如下(Base64编码):
X24= 1107
aWdo= 1108
IHRoYW4= 1109
- 构造前缀树(Trie)
# 词表: "a", "ab", "abc", "b"
root
├── a (是完整token)
│ ├── b (是完整token)
│ │ └── c (是完整token)
└── b (是完整token)
- 匹配算法(以BPE为例)
- 从当前位置开始,在前缀树中查找最长可能匹配
- 找到"abc"匹配成功
- 输出对应的Token ID
- 处理未知字符(OOV)
- 退回到字节级别编码(如UTF-8字节)
- 使用特殊token(如
<unk>)表示未知 - 或者拆分成更小的子词单元
Embedding: 对每个token结合语义和位置信息进行embedding
token首先在静态的向量矩阵里,找到属于自己的向量。在所有token都转换后,还会进行以下操作:
- input embedding: 对语义进行嵌入,
token在提前训练好的静态向量矩阵里,找到属于自己的向量 - position encoding: 为表示多个
token的相对位置,添加位置信息
Transformer: 计算KV
在得到向量后,向量将作为decoder结构的输入,在N个Transformer Decoder Blocks上进行计算
- Self-Attention(自注意力): 使用带有
Causal Mask的自注意力进行计算,确保模型在训练和推理过程中,都不能看到未来的token,进而达到训推一致。 - 概率分布: 最终通过
LM Head (Linear + Softmax) → logits得到下一个Token出现的概率分布
输出Token选择
- Temperature: 温度越大概率分布越平缓,因此创造性越强;反之就越稳定,不容易出现幻觉
- Top-k: 考虑最高概率的
k个token - Top-p: 动态调整候选集大小,只累积到概率和达到p的最小token集合 这里直接上一个代码更好理解
# 简化版流程
def select_next_token(logits, temperature=1.0, top_k=None, top_p=None):
"""
logits: [vocab_size] 每个token的未归一化分数
返回: 选择的token_id
"""
# 1. 应用温度参数
logits = logits / temperature
# 2. 转换为概率分布
probs = softmax(logits)
# 3. 应用top-k过滤(如果启用)
if top_k is not None:
probs = apply_top_k(probs, top_k)
# 4. 应用top-p过滤(如果启用)
if top_p is not None:
probs = apply_top_p(probs, top_p)
# 5. 从处理后的分布中采样
next_token = sample_from_distribution(probs)
return next_token
最后将生成的token再加入到prompt末尾,重新进行推理,这样一轮一轮直到输出终止符。